👋Hello World! I'm Dona!
머신러닝 정리도 시작하였습니다!✍️
우선은 1차적으로 공개용 노션에 정리하고 있지만, 공부를 하면서 계속 추가 되는 내용이 많을 것 같아서 블로그 업로드는 추후에 하려고 합니다. 열공합시다 Go for it!🔥🔥
노션 URL : https://imdona.notion.site/imdona/imdona-s-Notion-4c374b9978cf4bb08d7b71ee594fb44b
imdona's Notion
👋 Hi there! I'm Dona!
imdona.notion.site
🍎 intro
1. 인공지능 - 머신러닝 - 딥러닝 - 빅데이터의 관계
‘머신러닝’하면 빅데이터, 딥러닝, 인공지능이라는 말들이 따라오곤 하죠?
각각의 뜻과 관계성에 대해 알아봅시다! 아래 시각화된 벤다이어그램 이미지를 통해 쉽게 이해해보아요🥕

사진 사용을 원하시면 출처를 밝히고 사용해주세요✨
- 빅데이터(Big Data) : 말 그대로 빅데이터는 엄청 나게 많은 데이터들을 모으고, 보관, 처리, 분석하는 방법
- 인공지능(Artificial Intelligence) : 프로그램이 인간처럼 생각하고 행동하게 하는 학문
- 머신러닝(Machine Learning) : 데이터로부터 의사결정을 위한 패턴을 기계 스스로가 학습하는 알고리즘
- 딥러닝(Deep Learning) : 우선은 머신러닝의 기법 중 하나로, 인간의 뉴런의 모양을 영감을 받아서 만든 인공신경망(artificial neural network)을 이용한 알고리즘이라고 간단하게 생각합시다.(추가 포스팅 예정)
2. 일반적인 프로그램과 머신러닝의 차이?
- 일반적인 프로그램 : 사람이 직접 규칙을 알려준다
- 머신러닝 프로그램 : 기계가 직접 규칙을 알아낸다
Tom Mitchell (1988): A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on t, as measured by P, improves with experience E
톰 미첼(Tom Mitchell) : 기계가 학습을 한다는 것은, 프로그램이 특정 작업(T)을 하는 데 있어서 경험(E)을 통해 작업의 성능(P)을 향상시키는 것

여기서 경험(E)은 데이터를 말합니다. 데이터가 충분히 없으면 머신러닝을 할 수 없다고해요. (머신러닝이 과거에 비해 핫해진 이유이기도 하죠🔥)
3. 머신러닝이 hot해진 이유🔥
- 기계가 학습을 통해 성능향상을 시키는 데 쓸 수 있는 데이터 🆙
- 컴퓨터의 성능 🆙 ➡️ 머신러닝을 위한 연산이 빨라진다
- 활용성 증명 ➡️ 예를 들면, 우리가 자주 보는 유튜브 알고리즘은 시청데이터를 학습시켜 맞춤 영상과 광고를 보여줍니다. 시청데이터가 많을수록 정확해져 광고 효율이 증가하고, 광고주들의 투자도 증가하겠죠?💰 뿐만아니라 우리 유저들도 서비스에 대한 만족도도 👍
4. 유형별 머신러닝
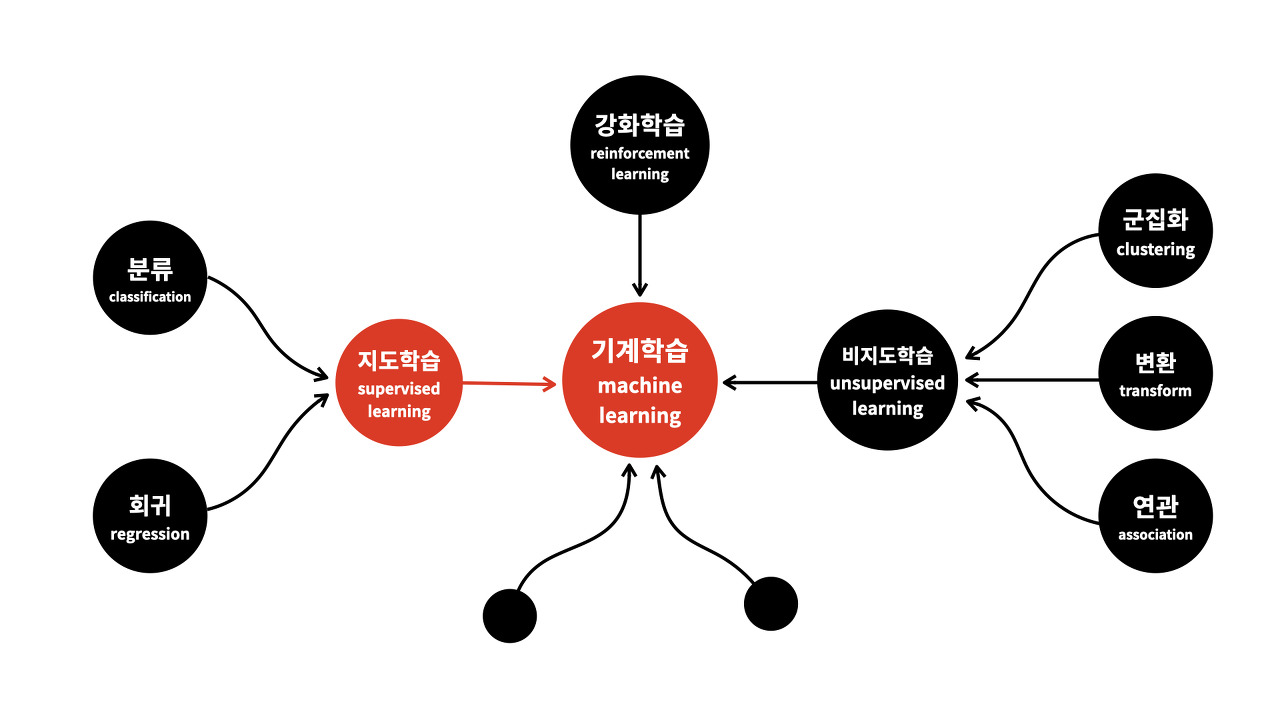
1. 지도 학습(Supervised Learning) : "답"이 있고, 이 답을 맞추는게 학습의 목적
- 분류(Classfication) : 맞춰야 하는 “답”이 숫자가 아님
- class(예측해야할 대상)를 예측 (categorical value)
- 예) 스팸메일 분류 프로그램
- 회귀(Regression) : 맞춰야 하는 “답”이 숫자
- 연속적인 값을 예측 (float value)
- 예) 아파트 가격 예측 프로그램
2. 비지도 학습(Unsupervised Learning) : "답"이 없고, 이 답을 맞추는게 학습의 목적
- 프로그램이 정답없이 "비슷한" 기준대로 묶음
- 예) 비슷한 기사를 찾는 프로그램 : 비슷함의 기준을 정해주지 않고, 기계가 직접 정하여 나눈다
3. 강화 학습(Reinforcement learning)
- 예) 알파고
REFERENCE
- codeit : https://www.codeit.kr/courses/machine-learning
- 생활코딩 : https://opentutorials.org/course/4548/28938
- Tom Mitchell image : http://www.cs.cmu.edu/~tom/
'🤖 AI & DATA > ML & DL' 카테고리의 다른 글
| [DL] Training Neural Network(신경망 학습) | Iteration(이터레이션) | 경사하강법(Gradient Descent, GD) | 옵티마이저(Optimizer) 알아보기 (0) | 2021.12.21 |
|---|
